大家好,我是贝克街的捉虫师呀!
还在为网页数据采集烦恼吗?手动复制粘贴太耗时,编写爬虫脚本又太复杂,更别提网站布局变化后还得重新修改代码。今天要介绍的这个开源项目 Maxun 就是为解决这些痛点而生的,它让网页数据采集变得前所未有的简单!
Maxun 是一个开源的无代码网页数据采集平台,其核心理念是通过可视化操作”训练”机器人来完成数据采集任务。项目采用 TypeScript 开发,目前在 GitHub 上已收获超过 10,000 颗星标,最近一天更是增长了 163 颗星,持续获得开发者的关注和认可。
🌟 核心特性
- 🤖 无代码操作
通过直观的可视化界面,只需简单点击就能创建数据采集机器人,2分钟即可完成训练,告别繁琐的代码编写。 - 📊 多样化采集模式
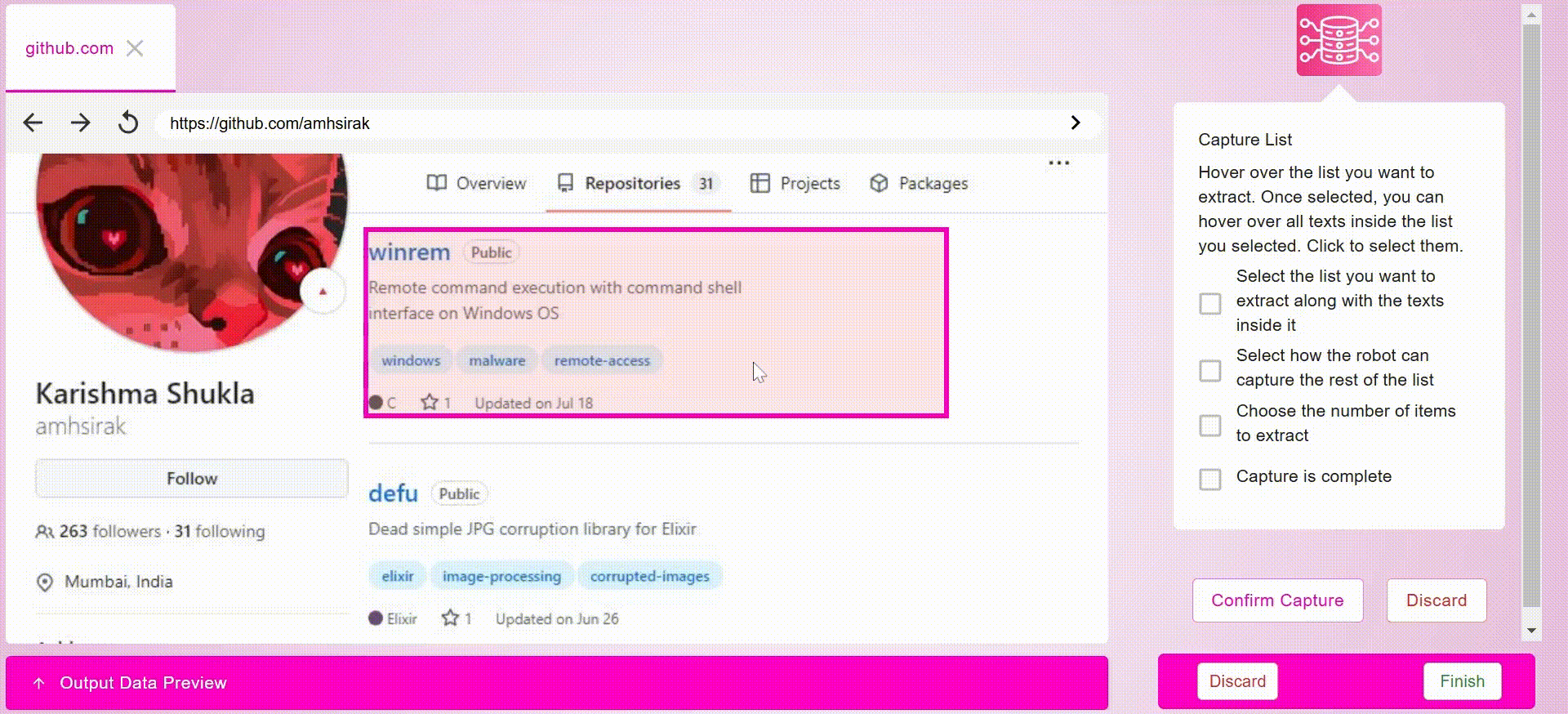
- Capture List:批量采集结构化数据,完美适配电商产品列表等场景
- Capture Text:精准提取特定文本内容
- Capture Screenshot:支持全页面或指定区域截图
- 🔄 智能调度与自动化
支持设置定时任务,让机器人按计划自动执行采集任务,同时能够自动处理分页和滚动加载。 - 🔌 丰富的集成能力
已支持 Google Sheets 集成,让采集数据自动同步至表格,更多集成正在开发中。
简单上手
- 环境准备
# Docker 方式(推荐)
docker-compose up -d
# 或传统安装方式
git clone https://github.com/getmaxun/maxun
cd maxun
npm install- 配置环境变量
创建.env文件并设置必要的配置项,包括数据库连接、端口设置等。 - 启动服务
完成配置后即可访问:
- 前端界面:http://localhost:5173
- 后端服务:http://localhost:8080
适用场景
- 电商数据采集
快速获取产品信息、价格变化等数据,支持批量采集。 - 内容监控
定期采集特定网页内容,追踪信息更新。 - 数据分析支持
将网页数据转化为结构化数据,便于后续分析处理。
推荐理由
- 真正的无代码体验,大幅降低使用门槛
- 自带反爬处理机制,支持自定义代理配置
- 开源免费,可自托管部署
- 活跃的开发维护,持续改进中
当然,作为一个早期阶段的项目,Maxun 也在积极开发更多功能,如自适应网站布局变化、登录验证支持等特性都已在计划中。对于有数据采集需求又不想陷入复杂技术细节的团队来说,Maxun 无疑是一个值得关注的选择。
项目地址:https://github.com/getmaxun/maxun
如果你也对这个项目感兴趣,欢迎去给个 Star 支持一下。使用过程中有任何问题或反馈,也可以通过项目的 Issue 区进行交流。
好了,今天的项目介绍就到这里,我们下期见!





